
Content #
“HPACK”算法是专门为压缩 HTTP 头部定制的算法,与 gzip、zlib 等压缩算法不同,它是一个“有状态”的算法,需要客户端和服务器各自维护一份“索引表”,也可以说是“字典”(这有点类似 brotli),压缩和解压缩就是查表和更新表的操作。
为了方便管理和压缩,HTTP/2 废除了原有的起始行概念,把起始行里面的请求方法、URI、状态码等统一转换成了头字段的形式,并且给这些“不是头字段的头字段”起了个特别的名字——“伪头字段”(pseudo-header fields)。而起始行里的版本号和错误原因短语因为没什么大用,顺便也给废除了。
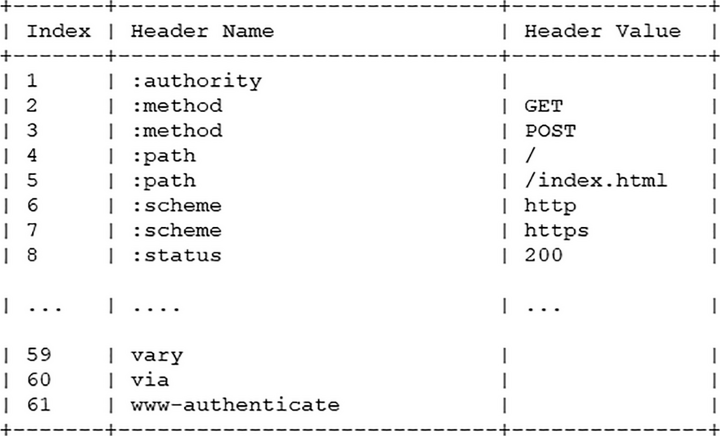
为了与“真头字段”区分开来,这些“伪头字段”会在名字前加一个“:”,比如“:authority” “:method” “:status”,分别表示的是域名、请求方法和状态码。
现在 HTTP 报文头就简单了,全都是“Key-Value”形式的字段,于是 HTTP/2 就为一些最常用的头字段定义了一个只读的“静态表”(Static Table)。
下面的这个表格列出了“静态表”的一部分,这样只要查表就可以知道字段名和对应的值,比如数字“2”代表“GET”,数字“8”代表状态码 200。
但如果表里只有 Key 没有 Value,或者是自定义字段根本找不到该怎么办呢?
这就要用到“动态表”(Dynamic Table),它添加在静态表后面,结构相同,但会在编码解码的时候随时更新。
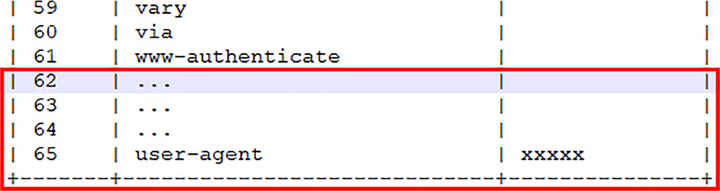
比如说,第一次发送请求时的“user-agent”字段长是一百多个字节,用哈夫曼压缩编码发送之后,客户端和服务器都更新自己的动态表,添加一个新的索引号“65”。那么下一次发送的时候就不用再重复发那么多字节了,只要用一个字节发送编号就好。
你可以想象得出来,随着在 HTTP/2 连接上发送的报文越来越多,两边的“字典”也会越来越丰富,最终每次的头部字段都会变成一两个字节的代码,原来上千字节的头用几十个字节就可以表示了,压缩效果比 gzip 要好得多。