
Content #
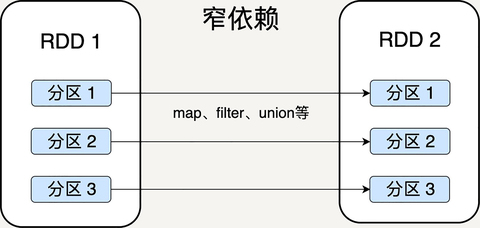
窄依赖就是父 RDD 的分区可以一一对应到子 RDD 的分区,宽依赖就是父 RDD 的每个分区可以被多个子 RDD 的分区使用。
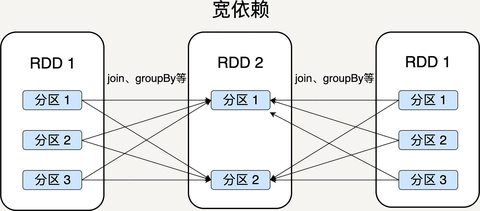
显然,窄依赖允许子 RDD 的每个分区可以被并行处理产生,而宽依赖则必须等父 RDD 的所有分区都被计算好之后才能开始处理。
一些转换操作如 map、filter 会产生窄依赖关系,而 Join、groupBy 则会生成宽依赖关系。因为 map 是将分区里的每一个元素通过计算转化为另一个元素,一个分区里的数据不会跑到两个不同的分区。而 groupBy 则要将拥有所有分区里有相同 Key 的元素放到同一个目标分区,而每一个父分区都可能包含各种 Key 的元素,所以它可能被任意一个子分区所依赖。
Spark 之所以要区分宽依赖和窄依赖是出于以下两点考虑:
- 窄依赖可以支持在同一个节点上链式执行多条命令,例如在执行了 map 后,紧接着执行 filter。相反,宽依赖需要所有的父分区都是可用的,可能还需要调用类似 MapReduce 之类的操作进行跨节点传递。
- 从失败恢复的角度考虑,窄依赖的失败恢复更有效,因为它只需要重新计算丢失的父分区即可,而宽依赖牵涉到 RDD 各级的多个父分区。