
Content #
Deployment 三个关键字段:
- replicas 定义了 Pod 的“期望数量”,Kubernetes 会自动维护 Pod 数量到正常水平。
- selector 定义了基于 labels 筛选 Pod 的规则,它必须与 template 里 Pod 的 labels 一致。
- template 定义了要运行的 Pod 模板。
Kubernetes 采用的是“贴标签”的方式,通过在 API 对象的“metadata”元信息里加各种标签(labels),我们就可以使用类似关系数据库里查询语句的方式,筛选出具有特定标识的那些对象。通过标签这种设计,Kubernetes 就解除了 Deployment 和模板里 Pod 的强绑定,把组合关系变成了“弱引用”。
下图用虚线特别标记了 matchLabels 和 labels 之间的联系。
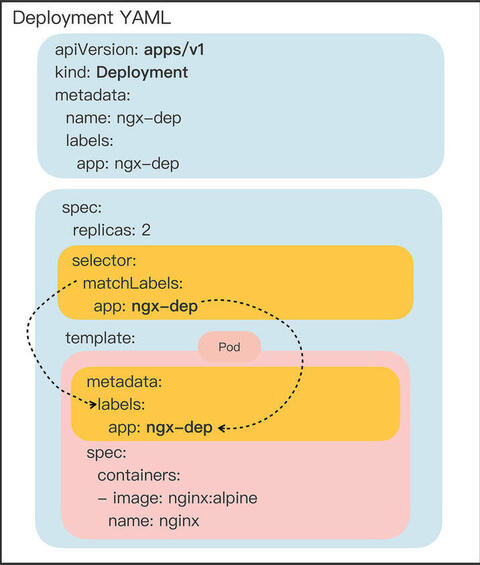
关键字段 selector,它的作用是“筛选”出要被 Deployment 管理的 Pod 对象,下属字段“matchLabels”定义了 Pod 对象应该携带的 label,它必须和“template”里 Pod 定义的“labels”完全相同,否则 Deployment 就会找不到要控制的 Pod 对象,apiserver 也会告诉你 YAML 格式校验错误无法创建。
为什么要这么麻烦?为什么不能像 Job 对象一样,直接用“template”里定义好的 Pod 就行了呢?
这是因为在线业务和离线业务的应用场景差异很大。离线业务中的 Pod 基本上是一次性的,只与这个业务有关,紧紧地绑定在 Job 对象里,一般不会被其他对象所使用。而在线业务就要复杂得多了,因为 Pod 永远在线,除了要在 Deployment 里部署运行,还可能会被其他的 API 对象引用来管理,比如负责负载均衡的 Service 对象。
所以 Deployment 和 Pod 实际上是一种松散的组合关系,Deployment 实际上并不“持有”Pod 对象,它只是帮助 Pod 对象能够有足够的副本数量运行,仅此而已。如果像 Job 那样,把 Pod 在模板里“写死”,那么其他的对象再想要去管理这些 Pod 就无能为力了。
- Pod 只能管理容器,不能管理自身,所以就出现了 Deployment,由它来管理 Pod。创建 Deployment 使用命令 kubectl apply,应用的扩容、缩容使用命令 kubectl scale。