
Content #
因为后缀子串的最后一个字符的位置是固定的,下标为 m-1,只需要记录长度就可以了。通过长度,可以确定一个唯一的后缀子串。

suffix 数组的下标 k,表示后缀子串的长度,下标对应的数组值存储的是,在模式串中跟好后缀{u}相匹配的子串{u*}的起始下标值。
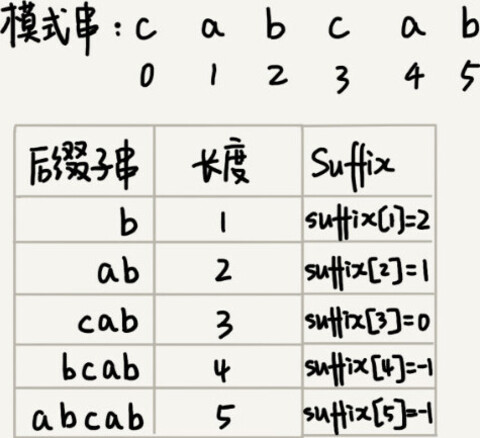
但是,如果模式串中有多个(大于 1 个)子串跟后缀子串{u}匹配,那 suffix 数组中该存储哪一个子串的起始位置呢?为了避免模式串往后滑动得过头了,肯定要存储模式串中最靠后的那个子串的起始位置,也就是下标最大的那个子串的起始位置。不过,这样处理就足够了吗?
实际上,仅仅是选最靠后的子串片段来存储是不够的。再回忆一下好后缀规则。
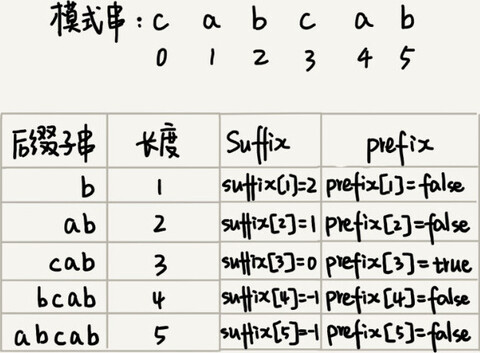
不仅要在模式串中,查找跟好后缀匹配的另一个子串,还要在好后缀的后缀子串中,查找最长的能跟模式串前缀子串匹配的后缀子串。
如果只记录刚刚定义的 suffix,实际上,只能处理规则的前半部分,也就是,在模式串中,查找跟好后缀匹配的另一个子串。所以,除了 suffix 数组之外,还需要另外一个 boolean 类型的 prefix 数组,来记录模式串的后缀子串是否能匹配模式串的前缀子串。
Viewpoints #
From #
33 | 字符串匹配基础(中):如何实现文本编辑器中的查找功能?