
Content #
最早提出 TSO 的,大概是 Google 的论文“ Large-scale Incremental Processing Using Distributed Transactions and Notifications”。这篇论文主要是介绍分布式存储系统 Percolator 的实现机制,其中提到通过一台 Oracle 为集群提供集中授时服务,称为 Timestamp Oracle。所以,后来的很多分布式系统也用它的缩写来命名自己的单点授时机制,比如 TiDB 和 Yahoo 的 Omid。
考虑到 TiDB 的使用更广泛些,这里主要介绍 TiDB 的实现方式。
TiDB 的全局时钟是一个数值,它由两部分构成,其中高位是物理时间,也就是操作系统的毫秒时间;低位是逻辑时间,是一个 18 位的数值。那么从存储空间看,1 毫秒最多可以产生 262,144 个时间戳(2^18),这已经是一个很大的数字了,一般来说足够使用了。
单点授时首先要解决的肯定是单点故障问题。TiDB 中提供授时服务的节点被称为 Placement Driver,简称 PD。多个 PD 节点构成一个 Raft 组,这样通过共识算法可以保证在主节点宕机后马上选出新主,在短时间内恢复授时服务。
那问题来了,如何保证新主产生的时间戳一定大于旧主呢?那就必须将旧主的时间戳存储起来,存储也必须是高可靠的,所以 TiDB 使用了 etcd。但是,每产生一个时间戳都要保存吗?显然不行,那样时间戳的产生速度直接与磁盘 I/O 能力相关,会存在瓶颈的。
如何解决性能问题呢?TiDB 采用预申请时间窗口的方式。
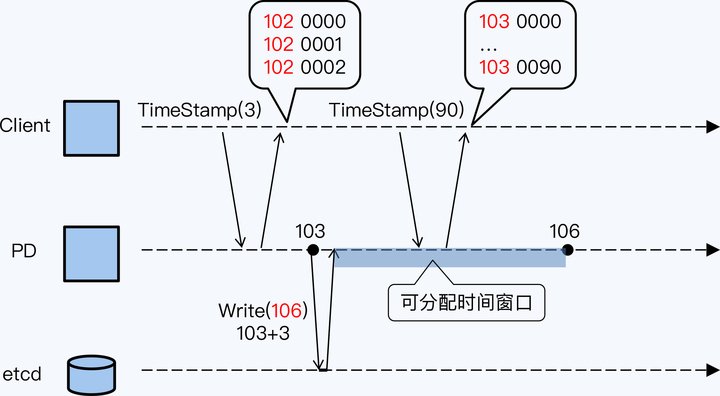
当前 PD(主节点)的系统时间是 103 毫秒,PD 向 etcd 申请了一个“可分配的时间窗口”。要知道时间窗口的跨度是可以通过参数指定的,系统的默认配置是 3 毫秒,示例采用了默认配置,所以这个窗口的起点是 PD 当前时间 103,时间窗口的终点就在 106 毫秒处。。写入 etcd 成功后,PD 将得到一个从 103 到 106 的“可分配时间窗口”,在这个时间窗口内 PD 可以使用系统的物理时间作为高位,拼接自己在内存中累加的逻辑时间,对外分配时间戳。
上述设计意味着,所有 PD 已分配时间戳的高位,也就是物理时间,永远小于 etcd 存储的最大值。那么,如果 PD 主节点宕机,新主就可以读取 etcd 中存储的最大值,在此基础上申请新的“可分配时间窗口”,这样新主分配的时间戳肯定会大于旧主了。
此外,为了降低通讯开销,每个客户端一次可以申请多个时间戳,时间戳数量作为参数,由客户端传给 PD。但要注意的是,一旦在客户端缓存,多个客户端之间时钟就不再是严格单调递增的,这也是追求性能需要付出的代价。