
Content #
有些分布式数据库会有一个限制条件,就是所有的 Leader 节点必须固定在同城主机房,而这就导致了资源使用率大幅下降。TiDB 和 OceanBase 都是这种情况。
Raft 协议下,所有读写都是发送到 Leader 节点,Follower 节点是没有太大负载的。Raft 协议的复制单位是分片级的,所以理论上一个节点可以既是一些分片的 Leader,又是另一些分片的 Follower。也就是说,通过 Leader 和 Follower 混合部署可以充分利用硬件资源。
但是如果主副本只能存在同一个机房,那就意味着另外三个机房的节点,也就是有整个集群五分之三的资源,在绝大多数时候都处于低负载状态。这显然是不经济的。
这个限制条件是怎么来的,一定要有吗?
其实,这个限制条件就是全局时钟导致的。具体来说,就是单时间源的授时服务器不能距离 Leader 太远,否则会增加通讯延迟,性能就受到很大影响,极端情况下还会出现异常。
增加延迟比较好理解,因为距离远了嘛。那异常是怎么回事呢?
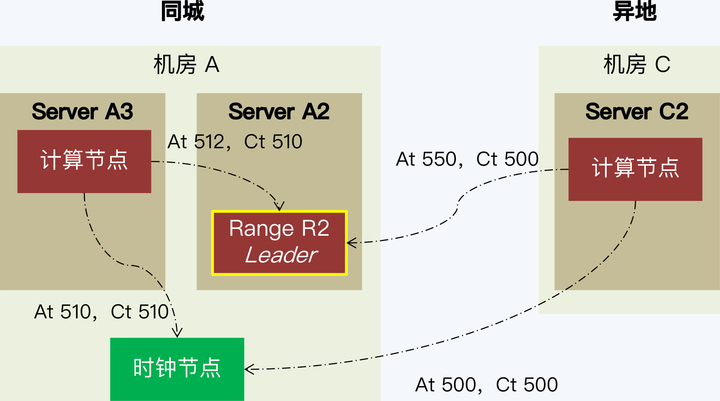
我们把这种异常称为“远端写入时间戳异常”,它的发生过程是这样的:
-
C2 节点与机房 A 的全局时钟服务器通讯,获取时间。此时绝对时间(At)是 500,而全局时钟(Ct)也是 500。
-
A3 节点也与全局时钟通讯,获取时间。A3 的请求晚于 C2,拿到的全局时钟是 510,此时的绝对时钟也是 510。
-
A3 节点要向 R2 写入数据,这个动作肯定是晚于取全局时钟的操作,所以绝对时间来到了 512,但是 A3 使用的时间戳仍然是 510。写入成功。
-
轮到 C2 节点向 R2 写入数据,由于 C2 在异地,通讯的时间更长,所以虽然 C2 先开始写入动作的流程,但却落后于 A3 将写入命令发送给 R2,此时绝对时间来到了 550,而 C2 使用的时间戳是 500。A3 与 C2 都要向 R2 写入数据,并且是相同的 Key,数据要相互覆盖的。这时候问题来了,R2 中已经有了一条记录时间戳是 510,已经提交成功,稍后又收到了一条时间戳是 500 的记录,这是 R2 只能拒绝 500 的这条记录。因为后写入的数据使用更早的时间戳,整个时间线就会乱掉,否则读取的进程会先看到 510 的数据,再看到 500 的数据,数据一致性显然有问题。
这个例子说明,如果远端计算节点距离时钟节点过远,那么当并发较大且事务冲突较多时,异地机房就会出现频繁的写入失败。这种业务场景并不罕见,当我们网购付款时就会出现多个事务在短时间内竞争修改商户的账户余额的情况。