
Content #
Tiered 策略之所以有严重的写放大和空间放大问题,主要是因为每次 Compact 需要全量数据参与,开销自然就很大。那么如果每次只处理小部分 SSTable 文件,就可以改善这个问题了。
Leveled 就是这个思路,它的设计核心就是将数据分成一系列 Key 互不重叠且固定大小的 SSTable 文件,并分层(Level)管理。同时,系统记录每个 SSTable 文件存储的 Key 的范围。Leveled 策略最先在 LevelDB 中使用,也因此得名。后来从 LevelDB 上发展起来的 RocksDB 也采用这个策略。
接下来,我们详细说明一下这个处理过程。
- 第一步处理 Leveled 和 Tiered 是一样的。当内存的数据较多时,就会 Flush 到 SSTable 文件。对应内存的这一层 SSTable 定义为 L0,其他层的文件我们同样采用 Ln 的形式表示,n 为对应的层数。因为 L0 的文件仍然是按照时间顺序生成的,所以文件之间就可能有重叠的 Key。L0 不做整理的原因是为了保证写盘速度。
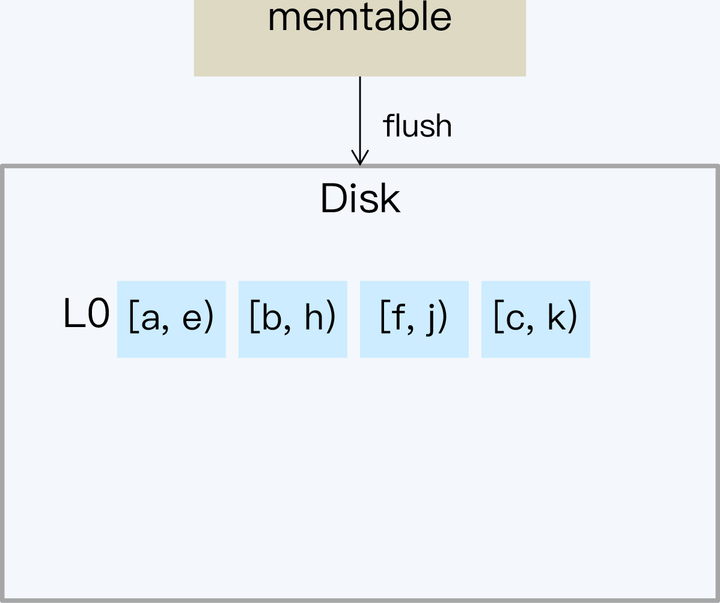
- 通常系统会通过指定 SSTable 数量和大小的方式控制每一个层的数据总量。当 L0 超过预定文件数量,就会触发 L0 向 L1 的 Compact。因为在 L0 的 SSTable 中 Key 是交叉的,所以要读取 L0 的所有 SSTable,写入 L1,完成后再删除 L0 文件。从 L1 开始,SSTable 都是保证 Key 不重叠的。
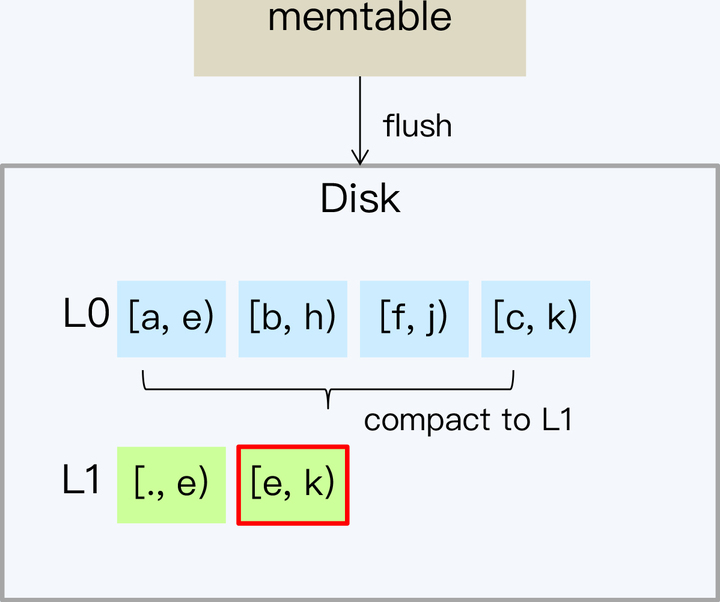
- 随着 L1 层数据量的增多,SSTable 可能会重新划分边界,目的是保证数据相对均衡的存储。
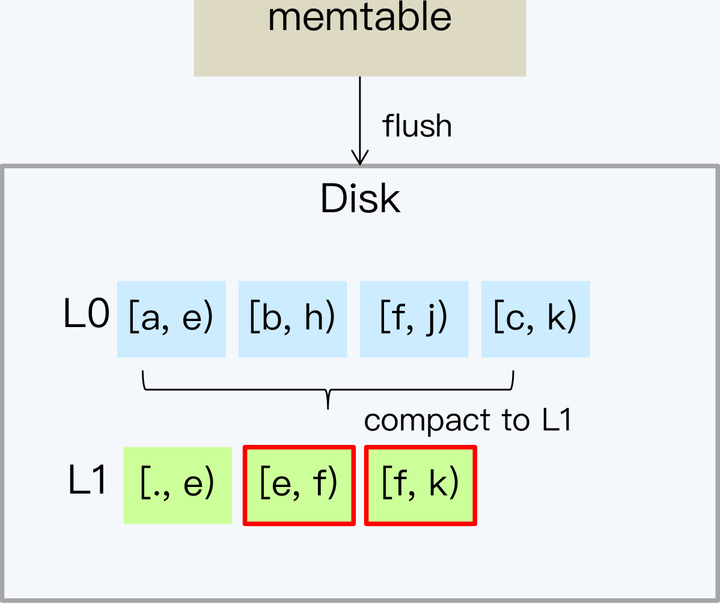
- 由于 L1 的文件大小和数量也是受限的,所以随着数据量的增加又会触发 L1 向 L2 的 Compact。因为 L1 的文件是不重叠的,所以不用所有 L1 的文件都参与 Compact,这就延缓了磁盘 I/O 的开销。而 L2 的单个文件容量会更大,通常从 L1 开始每层的存储数据量以 10 倍的速度增长。这样,每次 Ln 到 L(n+1) 的 compact 只会涉及少数的 SSTable,间隔的时间也会越来越长。
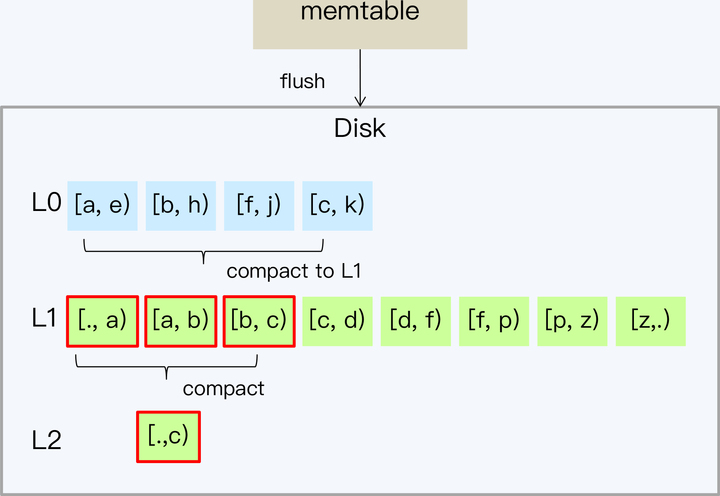
说完处理流程,我们再从 RUM 三个角度来分析下。
- 读放大
因为存在多个 SSTable,Leveled 策略显然是存在读放大的。因为 SSTable 是有序的,如果有 M 个文件,则整体计算的时间复杂度是 O(MlogN)。这个地方还可以优化。通常的方法是在 SSTable 中引入 Bloom Filter(BF),这是一个基于概率的数据结构,可以快速地确定一个 Key 是否存在。这样执行 Get 操作时,先读取每一个 SSTable 的 BF,只有这个 Key 存在才会真的去文件中查找。
那么对于多数 SSTable,时间复杂度是 O(1)。L0 层的 SSTable 无序,所有都需要遍历,而从 L1 层开始,每层仅需要查找一个 SSTable。那么优化后的整体时间复杂度就是 O(X+L-1+logN),其中 X 是 L0 的 SSTable 数量,L 是层数。
- 写放大
Leveled 策略对写放大是有明显改善的,除了 L0 以外,每次更新仅涉及少量 SSTable。但是 L0 的 Compact 比较频繁,所以仍然是读写操作的瓶颈。
- 空间放大
数据在同层的 SSTable 不重叠,这就保证了同层不会存在重复记录。而由于每层存储的数据量是按照比例递增的,所以大部分数据会存储在底层。因此,大部分数据是没有重复记录的,所以数据的空间放大也得到了有效控制。