
Content #
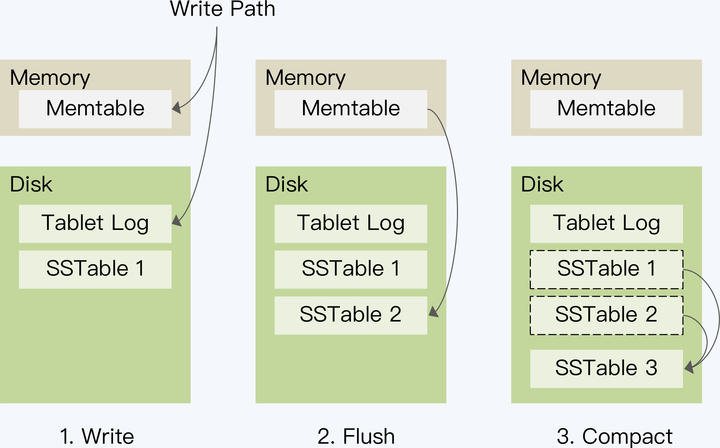
LSM 分成三步完成了数据的落盘。
-
第一步,写入 Memtable,同时记录 Tablet Log;
-
当 Memtable 的数据达到一定阈值后,系统会把其冻结并将其中的数据顺序写入磁盘上的有序文件(Sorted String Table,SSTable)中,这个操作被称为 Flush;当然,执行这个动作的同时,系统会同步创建一个新的 Memtable,处理写入请求。
-
根据第二步的处理逻辑,Memtable 会周期性地产生 SSTable。当满足一定的规则时,这些 SSTable 会被合并为一个大的 SSTable。这个操作称为 Compact。
与 B+Tree 的最大不同是 LSM 将随机写转换为顺序写,这样提升了写入性能。另外,Flush 操作不会像 B+Tree 那样产生写放大。
真正的写放大就发生在 Compact 这个动作上。Compact 有两个关键点,一是选择什么时候执行,二是要将哪些 SSTable 合并成一个 SSTable。这两点加起来称为“合并策略”。
我们刚刚在例子中描述的就是一种合并策略,称为 Size-Tiered Compact Strategy,简称 Tiered。BigTable 和 HBase 都采用了 Tiered 策略。它的基本原理是,每当某个尺寸的 SSTable 数量达到既定个数时,将所有 SSTable 合并成一个大的 SSTable。这种策略的优点是比较直观,实现简单,但是缺点也很突出。