
Content #
SNLJ 和 BNJ 都是直接在数据行上扫描,并没有使用索引。所以,这两种算法的磁盘 I/O 开销还是比较大的。
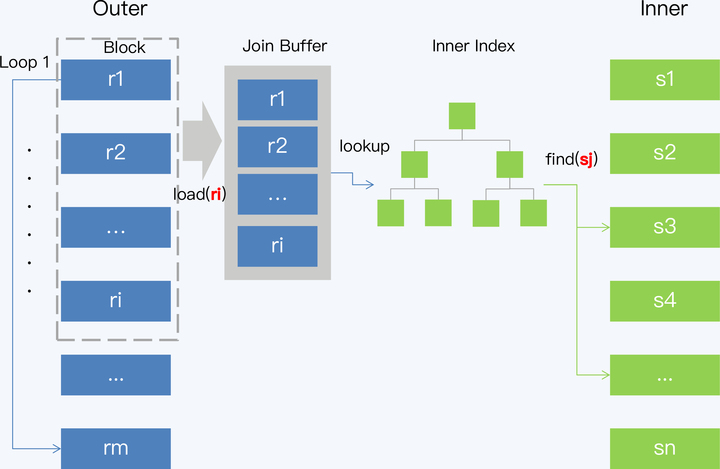
Index Lookup Join(ILJ)就是在 BNJ 的基础上使用了索引,算法执行过程是这样的:
- 遍历 Outer 表,取一个批次的记录 ri;
- 通过连接键(Join Key)和 ri 可以确定对 Inner 表索引的扫描范围,再通过索引得到对应的若干条数据记录,记为 sj;
- 将 ri 的每一条记录与 sj 的每一条记录做 Join 操作并输出结果;
- 重复前三步,直到遍历完 Outer 表中的所有数据,就得到了最后结果集。
ILJ 的主要优化点就是对 Inner 表进行索引扫描。
那么,为什么不让 Outer 表也做索引扫描呢?
Outer 表当然也可以走索引。但是,BNJ 在 Inner 表上要做多次全表扫描成本最高,所以 Inner 表上使用索引的效果最显著,也就成为了算法的重点。而对 Outer 表来说,因为扫描结果集要放入内存中暂存,这意味着它的记录数是比较有限的,索引带来的效果也就没有 Inner 表那么显著,所以在定义中没有强调这部分。