
Content #
从磁盘读数据发送到网络上去。如果我们自己写一个简单的程序,最直观的办法,自然是用一个文件读操作,从磁盘上把数据读到内存里面来,然后再用一个 Socket,把这些数据发送到网络上去。
File.read(fileDesc, buf, len);
Socket.send(socket, buf, len);
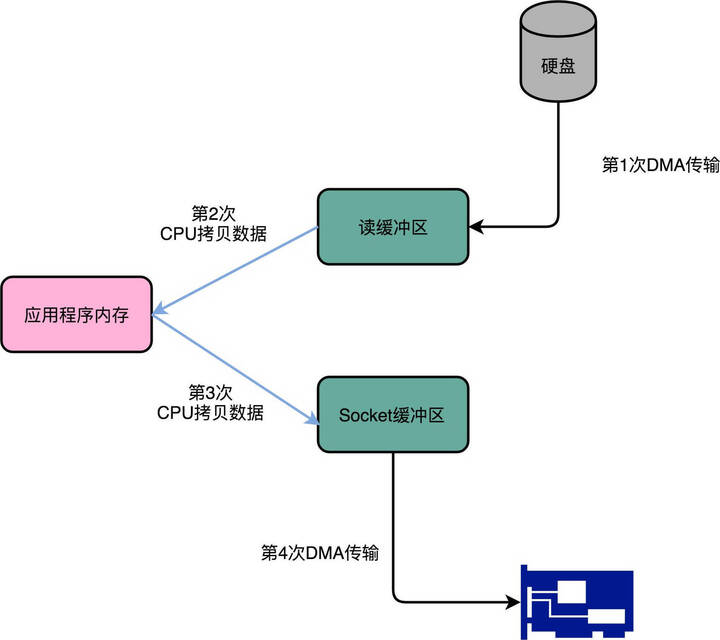
数据一共发生了四次传输的过程。
- 从硬盘上读到操作系统内核的缓冲区里。这个传输是通过 DMA 搬运的。
- 从内核缓冲区里面的数据,复制到应用分配的内存里面。这个传输是通过 CPU 搬运的。
- 从应用的内存里面,再写到操作系统的 Socket 的缓冲区里面去。这个传输,还是由 CPU 搬运的。
- 从 Socket 的缓冲区里面,写到网卡的缓冲区里面去。这个传输又是通过 DMA 搬运的。
Kafka 把这个数据搬运的次数,从四次,变成了两次,并且只有 DMA 来进行数据搬运,不需要 CPU。
@Override
public long transferFrom(FileChannel fileChannel, long position, long count) throws IOException {
return fileChannel.transferTo(position, count, socketChannel);
}
Kafka 的代码调用了 Java NIO 库,具体是 FileChannel 里面的 transferTo 方法。数据并没有读到中间的应用内存里面,而是直接通过 Channel,写入到对应的网络设备里。并且,对于 Socket 的操作,也不是写入到 Socket 的 Buffer 里面,而是直接根据描述符(Descriptor)写入到网卡的缓冲区里面。于是,在这个过程之中,只进行了两次数据传输。
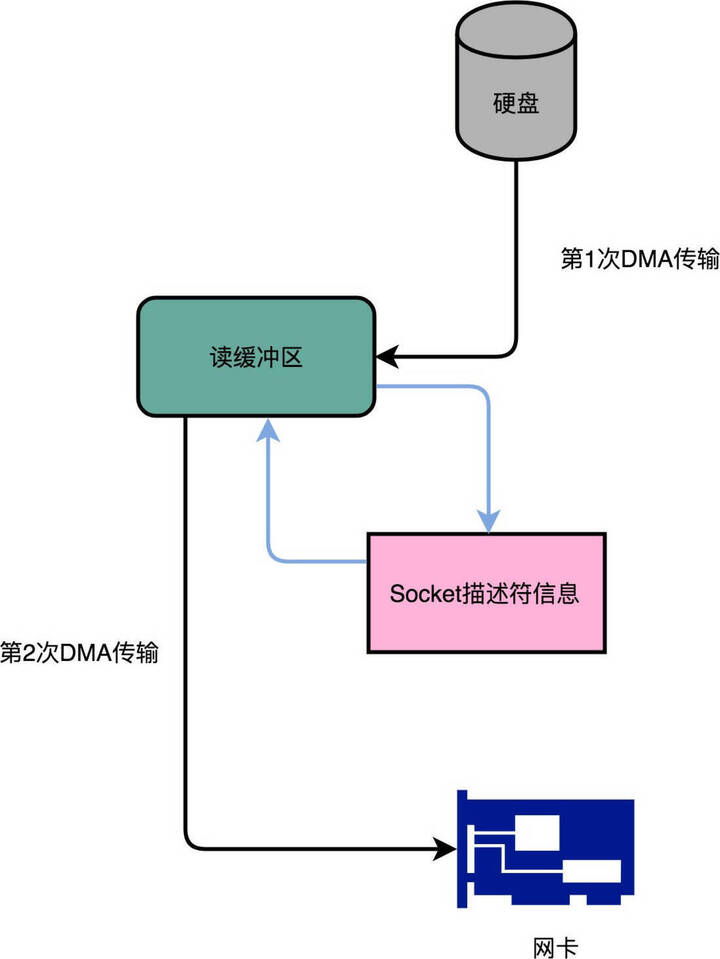
第一次,是通过 DMA,从硬盘直接读到操作系统内核的读缓冲区里面。第二次,则是根据 Socket 的描述符信息,直接从读缓冲区里面,写入到网卡的缓冲区里面。
在这个方法里面,我们没有在内存层面去“复制(Copy)”数据,所以这个方法,也被称之为零拷贝(Zero-Copy)。