
Content #
在 HBase 下,每个分片都有一个不重叠的 Key 区间,这个区间左闭右开。当新增一个键值对(Key/Value)时,系统会先判断这个 Key 与哪个分片的区间匹配,而后就分配到那个匹配的分片中保存,匹配算法一般采用左前缀匹配方式。
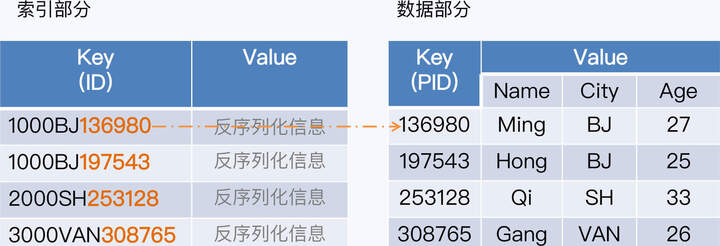
这个场景中,我们要操作的是一张用户信息表 T_USER,它有四个字段,分别是主键 PID、客户名称(Name)、城市(City)和年龄(Age)。T_USER 映射到 HBase 这样的键值系统后,主键 PID 作为 Key,其他数据项构成 Value。事实上,HBase 的存储格式还要更复杂些,这里为了便于你理解,做了简化。
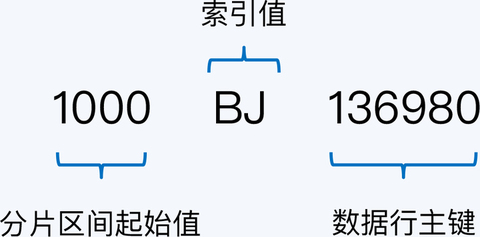
我们在“City”字段上建立索引,索引与数据行是一对一的关系(建立索引时所用的主键会生成下图所示的Key,会加上其他信息,不是只有City的值)。索引存储也是 KV 形式,Key 是索引自身的主键 ID,Value 是反序列化信息用于解析主键内容。索引主键由三部分构成,分别是分片区间起始值、索引值和所指向数据行的主键(PID)。因为 PID 是唯一的,索引主键在它的基础上增加了前缀,所以也必然是唯一的。
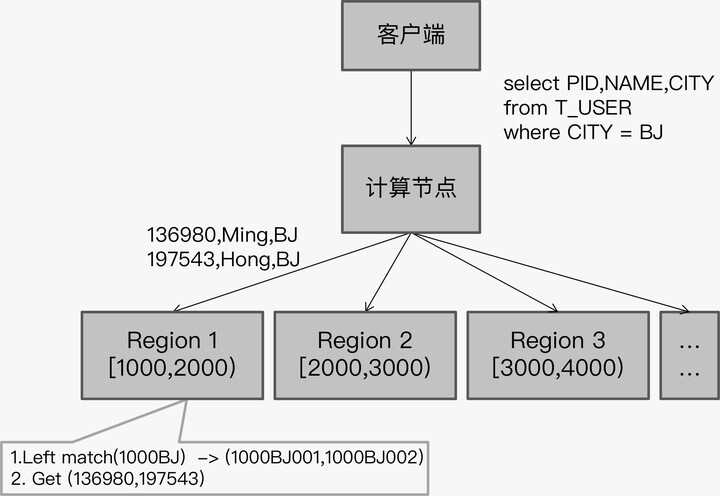
整个查询的流程是这样的:
- 客户端发起查询 SQL。
- 计算节点将 SQL 下推到各个存储节点。
- 存储节点在每个 Region 上执行下推计算,取 Region 的起始值加上查询条件中的索引值,拼接在一起作为左前缀,扫描索引数据行。
- 根据索引扫描结果中的 PID,回表查询。
- 存储节点将 Region 查询结果,反馈给计算节点。
- 计算节点汇总结果,反馈给客户端。
实现分区索引的难点在于如何始终保持索引与数据的同分布,尤其是发生分片分裂时,这是很多索引方案没有完美解决的问题。
Viewpoints #
From #
19 | 查询性能优化:计算与存储分离架构下有哪些优化思路?