
Content #
整个 2PC 的事务延迟由两个阶段组成,可以用公式表达为:
\[L_{txn}=L_{prep} + L_{commit}\]
其中,\(L_{prep}\) 是准备阶段的延迟,\(L_{commit}\) 是提交阶段的延迟。
我们先说准备阶段,它是事务操作的主体,包含若干读操作和若干写操作。我们把读操作的次数记为 R,读操作的平均延迟记为 Lr,写操作次数记为 W,写操作平均延迟记为 Lw。那么整个准备阶段的延迟可以用公式表达为:
\[L_{prep}=R*L_r + W*L_w\]
在不同的产品架构下,读操作的成本是不一样的。我们选一种最乐观的情况, CockroachDB。因为它采用 P2P 架构,每个节点既承担了客户端服务接入的工作,也有请求处理和数据存储的职能。所以,最理想的情况是,读操作的客户端接入节点,同时是当前事务所访问数据的 Leader 节点,那么所有读取就都是本地操作。
磁盘操作相对网络延迟来说是极短的,所以我们可以忽略掉读取时间。那么,准备阶段的延迟主要由写入操作决定,可以用公式表达为:
\[L_{prep}=W*L_w\]
分布式数据库的写入,并不是简单的本地操作,而是使用共识算法同时在多个节点上写入数据。所以,一次写入操作延迟等于一轮共识算法开销,我们用 Lc 代表一轮共识算法的用时,可以得到下面的公式:
\[L_{prep}=W*L_c\]
我们再来看第二阶段,提交阶段,使用 Percolator 的情况下,它的提交阶段只需要写入一次数据,修改整个事务的状态。对于 CockroachDB,这个事务标识可以保存在本地。那么提交操作的延迟也是一轮共识算法,也就是:
\[L_{commit}=L_c\]
分别得到两个阶段的延迟后,带入最开始的公式,可以得到:
\[L_{txn}=(W+1)*L_c\]
我们把这个公式带入具体例子里来看一下。
这次还是小明给小红转账,金额是 500 元。
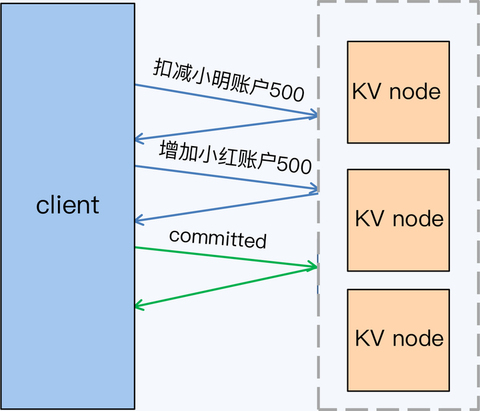
在这个转账事务中,包含两条写操作 SQL,分别是扣减小明账户余额和增加小红账户余额,W 等于 2。再加上提交操作,一共有 3 个 Lc。我们可以看到,这个公式里事务的延迟是与写操作 SQL 的数量线性相关的,而真实场景中通常都会包含多个写操作,那事务延迟肯定不能让人满意。