
Content #
假如有一张数据库表 test,目前有四条记录。
下面的例子就是关于 TiDB 如何处理下推的,我们首先来看这组 SQL。
begin;
insert into test (id, value, cond) values(‘5’,’V5’,’C4’);
select * from test where cond=’C4’;
SQL 的逻辑很简单,先插入一条记录后,再查询符合条件的所有记录。结合上一个例子中 test 表的数据存储情况,得到的查询结果应该是两条记录,一条是原有 ID 等于 4 的记录,另一条是刚插入的 ID 等于 5 的记录。这对单体数据库来说,是很平常的操作,但是对于 TiDB 来说,就是一个有挑战的事情了。
TiDB 采用了“缓存写提交”技术,就是将所有的写 SQL 缓存起来,直到事务 commit 时,再一起发送给存储节点。这意味着执行事务中的 select 语句时, insert 的数据还没有写入存储节点,而是缓存在计算节点上的,那么 select 语句下推后,查询结果将只有 ID 为 4 的记录,没有 ID 等于 5 的记录。
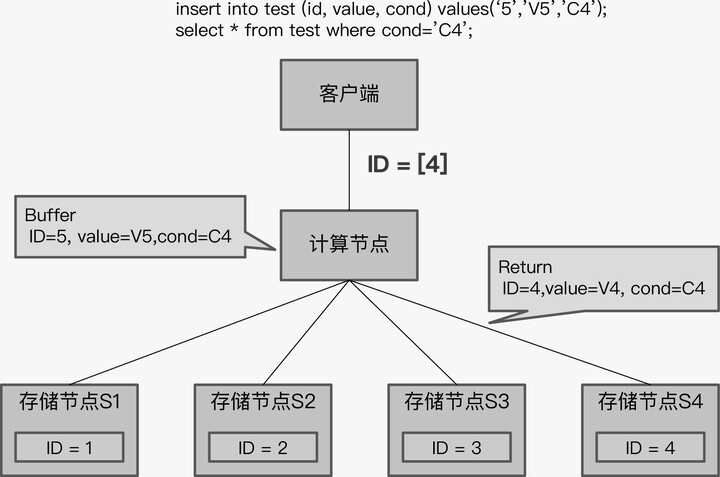
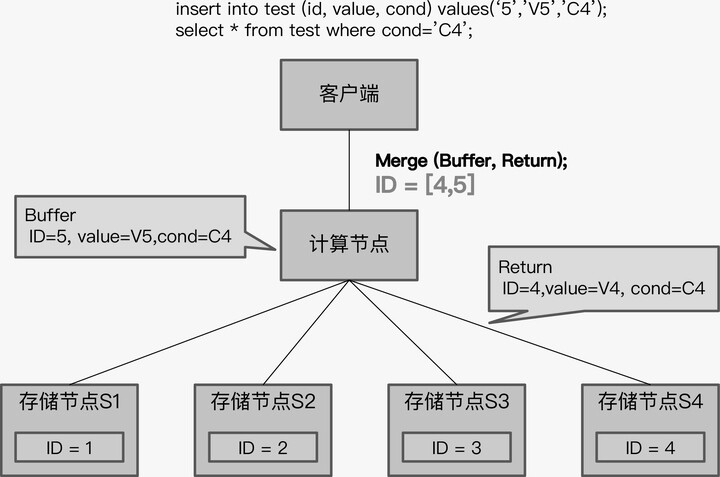
这个结果显然是错误的。为了解决这个问题,TiDB 开始的设计策略是,当计算节点没有缓存数据时,就执行下推,否则就不执行下推。
这种策略限制了下推的使用,对性能的影响很大。所以,之后 TiDB 又做了改进,将缓存数据也按照存储节点的方式组织成 Row 格式,再将缓存和存储节点返回结果进行 Merge,就得到了最后的结果。这样,缓存数据就不会阻碍读请求的下推了。
Viewpoints #
From #
19 | 查询性能优化:计算与存储分离架构下有哪些优化思路?