
Content #
分布式数据库的主体架构是朝着计算和存储分离的方向发展的,这一点在 NewSQL 架构中体现得尤其明显。但是计算和存储是一个完整的过程,架构上的分离会带来一个问题:是应该将数据传输到计算节点 (Data Shipping),还是应该将计算逻辑传输到数据节点 (Code Shipping)?
从直觉上说,肯定要选择 Code Shipping,因为 Code 的体量远小于 Data,因此它能传输得更快,让系统的整体性能表现更好。
这个将 code 推送到存储节点的策略被称为“计算下推”,是计算存储分离架构下普遍采用的优化方案。
将计算节点的逻辑推送到存储节点执行,避免了大量的数据传输,也达到了计算并行执行的效果。
假如有一张数据库表 test,目前有四条记录。
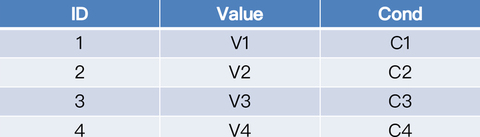
我们在客户端执行下面这条查询 SQL。
select value from test where cond=’C1’;
计算节点接到这条 SQL 后,会将过滤条件“cond=‘C1’“下推给所有存储节点。
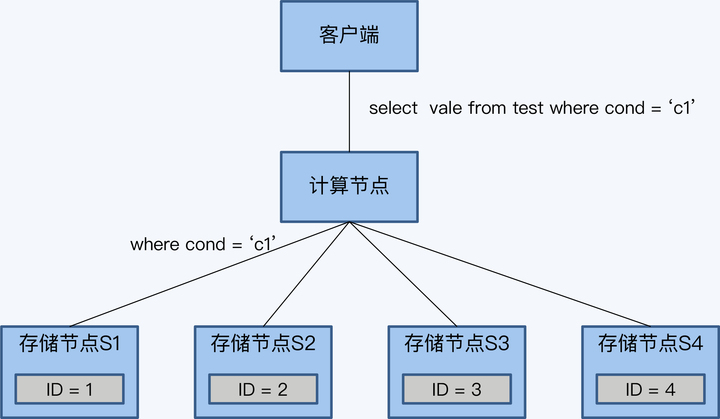
存储节点 S1 有符合条件的记录,则返回计算节点,其他存储节点没有符合的记录,返回空。计算节点直接将 S1 的结果集返回给客户端。
这个过程因为采用了下推方式,网络上没有无效的数据传输,否则,就要把四个存储节点的数据都送到计算节点来过滤。
这个例子是计算下推中比较典型的“谓词下推”(Predicate Pushdown),很直观地说明了下推的作用。这里的谓词下推,就是把查询相关的条件下推到数据源进行提前的过滤操作,表现形式主要是 Where 子句。
Viewpoints #
From #
19 | 查询性能优化:计算与存储分离架构下有哪些优化思路?