
Content #
假设投票信息的格式是 <proposedLeader, proposedEpoch, proposedLastZxid,node>,其中:
- proposedLeader,节点提议的,领导者的集群 ID,也就是在集群配置(比如 myid 配置文件)时指定的 ID。
- proposedEpoch,节点提议的,领导者的任期编号。
- proposedLastZxid,节点提议的,领导者的事务标识符最大值(也就是最新提案的事务标识符)。
- node,投票的节点,比如节点 B。
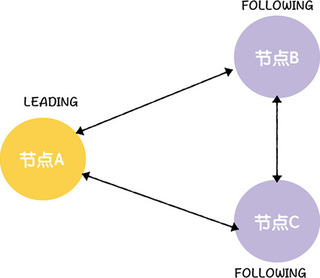
假设一个 ZooKeeper 集群,由节点 A、B、C 组成,其中节点 A 是领导者,节点 B、C 是跟随者(为了方便演示,假设 epoch 分别是 1 和 1,lastZxid 分别是 101 和 102,集群 ID 分别为 2 和 3)。那么如果节点 A 宕机了,会如何选举呢?
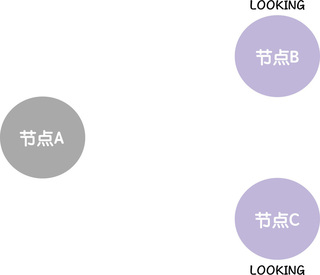
首先,当跟随者检测到连接领导者节点的读操作等待超时了,跟随者会变更节点状态,将自己的节点状态变更成 LOOKING,然后发起领导者选举(为了演示方便,我们假设这时节点 B、C 都已经检测到了读操作超时):
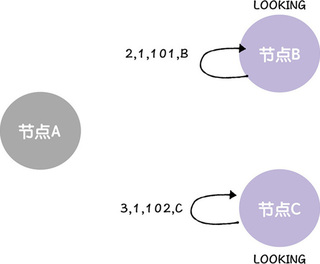
接着,每个节点会创建一张选票,这张选票是投给自己的,也就是说,节点 B、 C 都“自告奋勇”推荐自己为领导者,并创建选票 <2, 1, 101, B> 和 <3, 1, 102, C>,然后各自将选票发送给集群中所有节点,也就是说,B 发送给 B、C, C 也发送给 B、C。
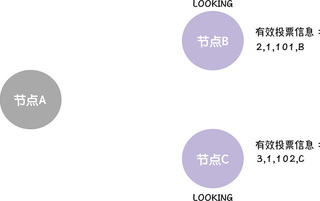
一般而言,节点会先接收到自己发送给自己的选票(因为不需要跨节点通讯,传输更快),也就是说,B 会先收到来自 B 的选票,C 会先收到来自 C 的选票:
需要你注意的是,集群的各节点收到选票后,为了选举出数据最完整的节点,对于每一张接收到选票,节点都需要进行领导者 PK,也就将选票提议的领导者和自己提议的领导者进行比较,找出更适合作为领导者的节点,约定的规则如下:
- 优先检查任期编号(Epoch),任期编号大的节点作为领导者;
- 如果任期编号相同,比较事务标识符的最大值,值大的节点作为领导者;
- 如果事务标识符的最大值相同,比较集群 ID,集群 ID 大的节点作为领导者。
如果选票提议的领导者,比自己提议的领导者,更适合作为领导者,那么节点将调整选票内容,推荐选票提议的领导者作为领导者。
当节点 B、C 接收到的选票后,因为选票提议的领导者与自己提议的领导者相同,所以,领导者 PK 的结果,是不需要调整选票信息,那么节点 B、C,正常接收和保存选票就可以了。
接着节点 B、C 分别接收到来自对方的选票,比如 B 接收到来自 C 的选票,C 接收到来自 B 的选票:
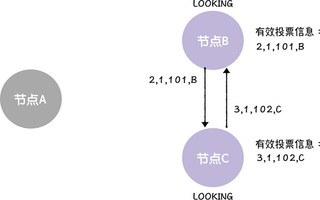
对于 C 而言,它提议的领导者是 C,而选票(<2, 1, 101, B>)提议的领导者是 B,因为节点 C 的任期编号与节点 B 相同,但节点 C 的事务标识符的最大值比节点 B 的大,那么,按照约定的规则,相比节点 B,节点 C 更适合作为领导者,也就是说,节点 C 不需要调整选票信息,正常接收和保存选票就可以了。
但对于对于节点 B 而言,它提议的领导者是 B,选票(<3, 1, 102, C>)提议的领导者是 C,因为节点 C 的任期编号与节点 B 相同,但节点 C 的事务标识符的最大值比节点 B 的大,那么,按照约定的规则,相比节点 B,节点 C 应该作为领导者,所以,节点 B 除了接收和保存选票信息,还会更新自己的选票为 <3, 1, 102, B>,也就是推荐 C 作为领导者,并将选票重新发送给节点 B、C:
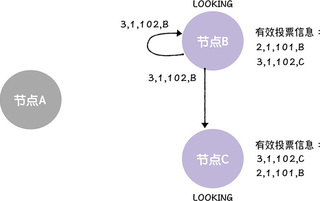
接着,当节点 B、C 接收到来自节点 B,新的选票时,因为这张选票(<3, 1, 102, B>)提议的领导者,与他们提议的领导者是一样的,都是节点 C,所以,他们正常接收和存储这张选票,就可以。
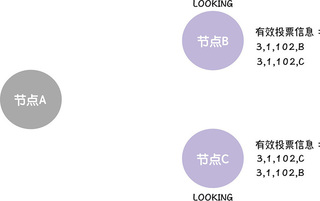
最后,因为此时节点 B、C 提议的领导者(节点 C)赢得大多数选票了(2 张选票),那么,节点 B、C 将根据投票结果,变更节点状态,并退出选举。比如,因为当选的领导者是节点 C,那么节点 B 将变更状态为 FOLLOWING,并退出选举,而节点 C 将变更状态为 LEADING,并退出选举。
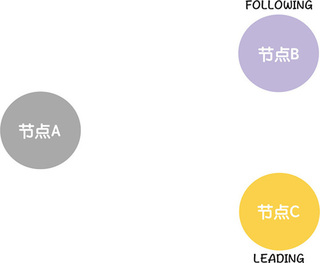
你看,这样我们就选举出新的领导者(节点 C),这个选举的过程,很容易理解,我在这里只是假设了一种选举的情况,还会存在节点间事务标识符相同、节点在广播投票信息前接收到了其他节点的投票等情况。
领导者选举的目标,是从大多数节点中选举出数据最完整的节点,也就是大多数节点中,事务标识符值最大的节点。另外,ZAB 本质上是通过“见贤思齐,相互推荐”的方式来选举领导者的。也就说,根据领导者 PK,节点会重新推荐更合适的领导者,最终选举出了大多数节点中数据最完整的节点。