
Content #
如果底层存储是一份数据,那么天然就可以保证 OLTP 和 OLAP 的数据一致性,这是 PAX 的最大优势,但是由于访问模式不同,性能的相互影响似乎也是无法避免,只能尽力选择一个平衡点。TiDB 展现了一种不同的思路,介于 PAX 和传统 OLAP 体系之间,那就是 OLTP 和 OLAP 采用不同的存储方式,物理上是分离的,然后通过创新性的复制策略,保证两者的数据一致性。
TiDB 是在较早的版本中就提出了 HTAP 这个目标,并增加了 TiSpark 作为 OLAP 的计算引擎,但仍然共享 OLTP 的数据存储 TiKV,所以两种任务之间的资源竞争依旧不可避免。直到近期的 4.0 版本中,TiDB 正式推出了 TiFlash 作为 OLAP 的专用存储。
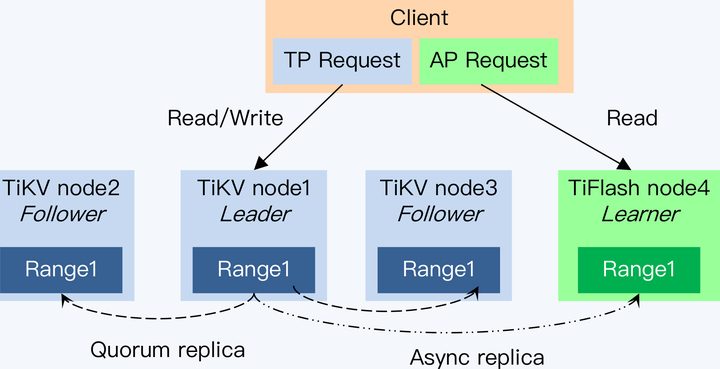
我们的关注点集中在 TiFlash 与 TiKV 之间的同步机制上。其实,这个同步机制仍然是基于 Raft 协议的。TiDB 在 Raft 协议原有的 Leader 和 Follower 上增加了一个角色 Learner。这个 Learner 和 Paxos 协议中的同名角色,有类似的职责,就是负责学习已经达成一致的状态,但不参与投票。这就是说,Raft Group 在写入过程中统计多数节点时,并没有包含 Learner,这样的好处是 Learner 不会拖慢写操作,但带来的问题是 Learner 的数据更新必然会落后于 Leader。
看到这里,你可能会问,这不就是一个异步复制吗,换了个马甲而已,有啥创新的。这也保证不了 AP 与 TP 之间的数据一致性吧?
Raft 协议能够实现数据一致性,是因为限制了只有主节点提供服务,否则别说是 Learner 就是 Follower 直接对外服务,都不能满足数据一致性。所以,这里还有另外一个设计。
Learner 每次接到请求后,首先要确认本地的数据是否足够新,而后才会执行查询操作。怎么确认足够新呢? Learner 会拿着读事务的时间戳向 Leader 发起一次请求,获得 Leader 最新的 Commit Index,就是已提交日志的顺序编号。然后,就等待本地日志继续 Apply,直到本地的日志编号等于 Commit Index 后,数据就足够新了。而在本地 Region 副本完成同步前,请求会一直等待直到超时。
这里,你可能又会产生疑问。这种同步机制有效运转的前提是 TiFlash 不能落后太多,否则每次请求都会带来数据同步操作,大量请求就会超时,也就没法实际使用了。但是,TiFlash 是一个列式存储,列式存储的写入性能通常不好, TiFlash 怎么能够保持与 TiKV 接近的写入速度呢?
这就要说到 TiFlash 的存储引擎 Delta Tree,它参考了 B+ Tree 和 LSM-Tree 的设计,分为 Delta Layer 和 Stable Layer 两层,其中 Delta Layer 保证了写入具有较高的性能。因为目前还没有向你介绍过存储引擎的背景知识,所以这里不再展开 Delta Tree 的内容了,我会在第 22 讲再继续讨论这个话题。
当然,TiFlash 毕竟是 OLAP 系统,首要目标是保证读性能,因此写入无论多么重要,都要让位于读优化。作为分布式系统,还有最后一招可用,那就是通过扩容降低单点写入的压力。