
Content #
哈希算法有个明显的缺点:当需要变更集群数时(比如从 2 个集群扩展为 3 个集群),这时大部分的数据都需要迁移,重新映射,数据的迁移成本是非常高的。
以增加节点和移除节点为例,具体说一说一致哈希是如何避免上面的问题的。假设,现在有一个节点故障了(比如节点 C):
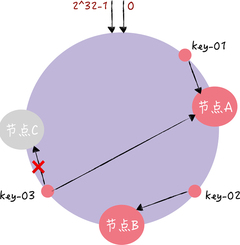
key-01 和 key-02 不会受到影响,只有 key-03 的寻址被重定位到 A。一般来说,在一致哈希算法中,如果某个节点宕机不可用了,那么受影响的数据仅仅是,会寻址到此节点和前一节点之间的数据。比如当节点 C 宕机了,受影响的数据是会寻址到节点 B 和节点 C 之间的数据(例如 key-03),寻址到其他哈希环空间的数据(例如 key-01),不会受到影响。
那如果此时集群不能满足业务的需求,需要扩容一个节点(也就是增加一个节点,比如 D):
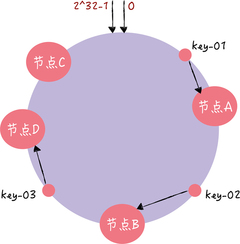
key-01、key-02 不受影响,只有 key-03 的寻址被重定位到新节点 D。一般而言,在一致哈希算法中,如果增加一个节点,受影响的数据仅仅是,会寻址到新节点和前一节点之间的数据,其它数据也不会受到影响。
让我们一起来看一个例子。使用一致哈希的话,对于 1000 万 key 的 3 节点 KV 存储,如果我们增加 1 个节点,变为 4 节点集群,只需要迁移 24.3% 的数据。
使用了一致哈希后,我们需要迁移的数据量仅为使用哈希算法时的三分之一,大大提升了效率。
总的来说,使用了一致哈希算法后,扩容或缩容的时候,都只需要重定位环空间中的一小部分数据。也就是说,一致哈希算法具有较好的容错性和可扩展性。
Viewpoints #
From #
10 | 一致哈希算法:如何分群,突破集群的“领导者”限制?