
Content #
CockroachDB 的解决方案是使用 Gossip 协议。你是不是想问,为什么不用 Paxos 协议呢?
这是因为 Paxos 协议本质上是一种广播机制,也就是由一个中心节点向其他节点发送消息。当节点数量较多时,通讯成本就很高。
CockroachDB 采用了 P2P 架构,每个节点都要保存完整的元数据,这样节点规模就非常大,当然也就不适用广播机制。而 Gossip 协议的原理是谣言传播机制,每一次谣言都在几个人的小范围内传播,但最终会成为众人皆知的谣言。这种方式达成的数据一致性是 “最终一致性”,即执行数据更新操作后,经过一定的时间,集群内各个节点所存储的数据最终会达成一致。
看到这,你可能有点晕。我们在第 2 讲就说过分布式数据库是强一致性的,现在搞了个最终一致性的元数据,能行吗?
这里我先告诉你结论,CockroachDB 真的是基于“最终一致性”的元数据实现了强一致性的分布式数据库。我画了一张图,我们一起走下这个过程。
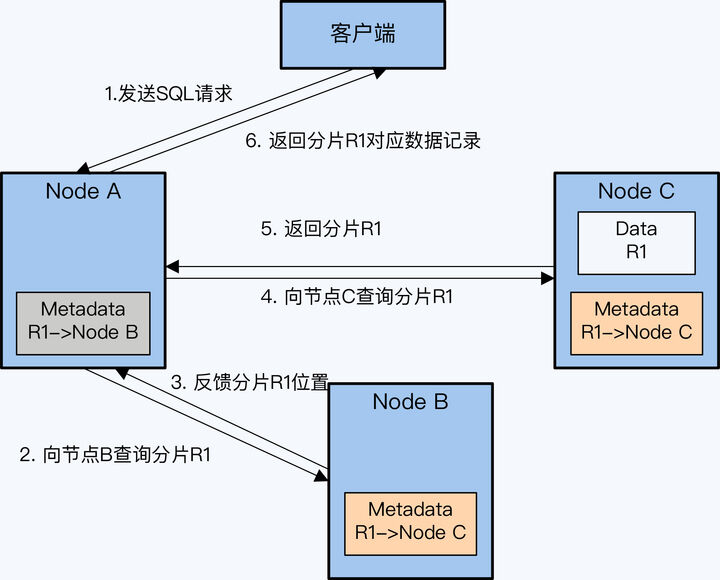
- 节点 A 接到客户端的 SQL 请求,要查询数据表 T1 的记录,根据主键范围确定记录可能在分片 R1 上,而本地元数据显示 R1 存储在节点 B 上。
- 节点 A 向节点 B 发送请求。很不幸,节点 A 的元数据已经过时,R1 已经重新分配到节点 C。
- 此时节点 B 会回复给节点 A 一个非常重要的信息,R1 存储在节点 C。
- 节点 A 得到该信息后,向节点 C 再次发起查询请求,这次运气很好 R1 确实在节点 C。
- 节点 A 收到节点 C 返回的 R1。
- 节点 A 向客户端返回 R1 上的记录,同时会更新本地元数据。
可以看到,CockroachDB 在寻址过程中会不断地更新分片元数据,促成各节点元数据达成一致。
复制协议的选择和数据副本数量有很大关系:如果副本少,参与节点少,可以采用广播方式,也就是 Paxos、Raft 等协议;如果副本多,节点多,那就更适合采用 Gossip 协议。