
Content #
该算法首次提出是在论文“Consistent Hashing and Random Trees : Distributed Caching Protocols for Relieving Hot Spots on the World Wide Web”当中。
要在工业实践中应用一致性 Hash 算法,首先会引入虚拟节点,每个虚拟节点就是一个分片。为了便于说明,我们在这个案例中将分片数量设定为 16。但实际上,因为分片数量决定了集群的最大规模,所以它通常会远大于初始集群节点数。
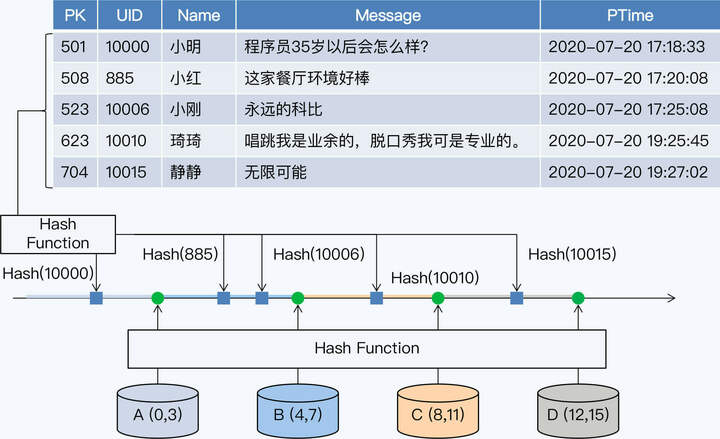
16 个分片构成了整个 Hash 空间,数据记录的主键和节点都要通过 Hash 函数映射到这个空间。这个 Hash 空间是一个 Hash 环。我们换一种方式画图,可以看得更清楚些。
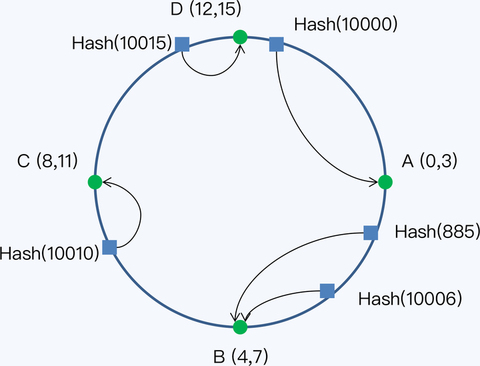
节点和数据都通过 Hash 函数映射到 Hash 环上,数据按照顺时针找到最近的节点。
当我们新增一台服务器,即节点 E 时,受影响的数据仅仅是新服务器到其环空间中前一台服务器(即沿着逆时针方向的第一台服务器)之间数据。结合我们的示例,只有小红分享的消息从节点 B 被移动到节点 E,其他节点的数据保持不变。此后,节点 B 只存储 Hash 值 6 和 7 的消息,节点 E 存储 Hash 值 4 和 5 的消息。
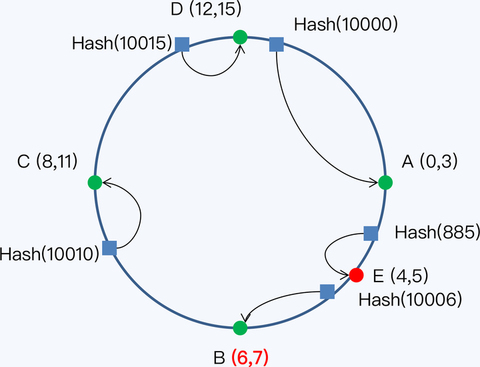
Hash 函数的优点是数据可以较为均匀地分配到各节点,并发写入性能更好。
本质上,Hash 分片是一种静态分片方式,必须在设计之初约定分片的最大规模。同时,因为 Hash 函数已经过滤掉了业务属性,也很难解决访问业务热点问题。所谓业务热点,就是由于局部的业务活跃度较高,形成系统访问上的热点。这种情况普遍存在于各类应用中,比如电商网站的某个商品卖得比较好,或者外卖网站的某个饭店接单比较多,或者某个银行网点的客户业务量比较大等等。