Content #
可编程管线(Programable Function Pipeline)时候的 GPU,有两类 Shader,也就是 Vertex Shader 和 Fragment Shader。在进行顶点处理的时候,我们操作的是多边形的顶点;在片段操作的时候,我们操作的是屏幕上的像素点。对于顶点的操作,通常比片段要复杂一些。所以一开始,这两类 Shader 都是独立的硬件电路,也各自有独立的编程接口。因为这么做,硬件设计起来更加简单,一块 GPU 上也能容纳下更多的 Shader。
不过呢,大家很快发现,虽然我们在顶点处理和片段处理上的具体逻辑不太一样,但是里面用到的指令集可以用同一套。而且,虽然把 Vertex Shader 和 Fragment Shader 分开,可以减少硬件设计的复杂程度,但是也带来了一种浪费,有一半 Shader 始终没有被使用。在整个渲染管线里,Vertext Shader 运行的时候,Fragment Shader 停在那里什么也没干。Fragment Shader 在运行的时候, Vertext Shader 也停在那里发呆。
本来 GPU 就不便宜,结果设计的电路有一半时间是闲着的。喜欢精打细算抠出每一分性能的硬件工程师当然受不了了。于是,统一着色器架构(Unified Shader Architecture)就应运而生了。
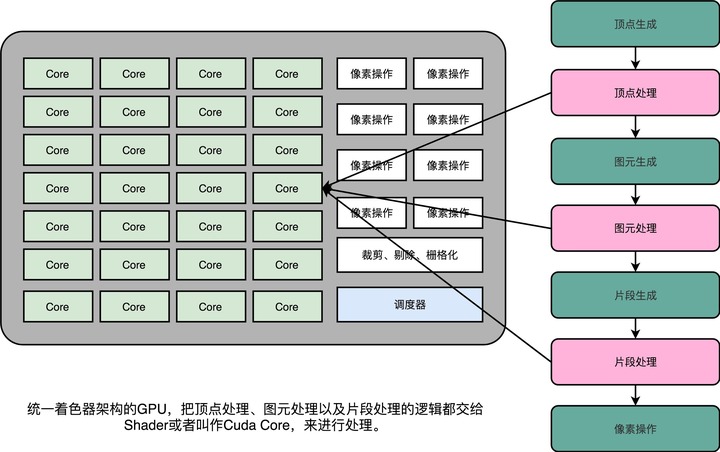
既然大家用的指令集是一样的,那不如就在 GPU 里面放很多个一样的 Shader 硬件电路,然后通过统一调度,把顶点处理、图元处理、片段处理这些任务,都交给这些 Shader 去处理,让整个 GPU 尽可能地忙起来。这样的设计,就是我们现代 GPU 的设计,就是统一着色器架构。
有意思的是,这样的 GPU 并不是先在 PC 里面出现的,而是来自于一台游戏机,就是微软的 XBox 360。后来,这个架构才被用到 ATI 和 NVidia 的显卡里。这个时候的“着色器”的作用,其实已经和它的名字关系不大了,而是变成了一个通用的抽象计算模块的名字。
正是因为 Shader 变成一个“通用”的模块,才有了把 GPU 拿来做各种通用计算的用法,也就是 GPGPU(General-Purpose Computing on Graphics Processing Units,通用图形处理器)。而正是因为 GPU 可以拿来做各种通用的计算,才有了过去 10 年深度学习的火热。