
Content #
我们可以编写如下所示的一段文本内容,并将它保存到项目根目录下名为 Makefile 的文件内。通过在该文件所在目录下直接执行 make 命令,项目得以被正确编译。
bin/main: src/main.c src/mod.c
gcc src/main.c src/mod.c -I./include -lm -o bin/main
不使用make之前,每一次代码修改后,由于直接运行编译命令导致“全量编译”,进而带来的开发效率下降。
make 命令在每次实际进行编译前,都会首先追踪各个编译目标与其依赖项的版本信息(通常为“最后修改时间”)。而只有当相关依赖的内容在上一次编译后发生改变,或目标文件不存在时,才会再次编译该目标。通过这种方式,我们可以将大部分时间内的项目编译过程都集中在必要的几个源文件上,而不用“浪费”已编译好的其他中间目标文件。
接下来,我们尝试进一步优化 Makefile 中的配置项,来让最终的二进制编译目标与各个中间依赖项作进一步分离。并且,通过抽离编译命令中的可配置部分,我们也可以让整个编译脚本变得更具可读性与可用性。优化后的文件内容如下所示:
# 用于控制编译细节的自定义宏;
CC = gcc
CFLAGS = -I./include
LDFLAGS = -lm
TARGET_FILE = bin/main
# 描述各个目标的详细编译步骤;
$(TARGET_FILE): $(patsubst src/%.c,src/%.o,$(wildcard src/*.c))
$(CC) $^ $(LDFLAGS) -o $@
src/%.o: src/%.c include/%.h
$(CC) $< $(CFLAGS) -c -o $@ #do not link
Makefile 相关语法元素的含义在下面的表格中:
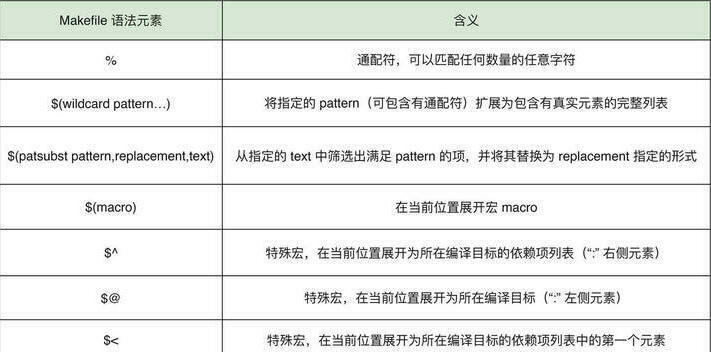
可以看到,通过以 “#” 开头的注释信息,我们将整个 Makefile 文件的内容划分成了两个部分。
第一部分包含用户可配置的一些宏常量,这些宏将在 make 运行时被替换到下面已经配置好的具体编译命令中。这样,用户可以通过修改这些量值来在一定范围内自定义期望使用的编译流程。
而第二部分则对应于各个编译目标的具体编译细节,这里我们将最初的那条编译命令拆分成了如下两步:
- 编译器将 src 与 include 文件夹内同名的 .c 与 .h 文件编译为对应的 .o 对象文件;
- 编译器将所有的 .o 文件一次性编译,并生成最后的二进制可执行文件。
利用这种方式,我们增加了可复用的中间编译结果,使通过 make 命令进行的每一次编译过程,都仅局限在被修改的 .c 或同名的 .h 文件上。如此一来,我们便可以做到最大程度上的“中间结果复用化”。
Makefile 帮助我们很好地解决了单一编译命令具有的可读性低、中间结果复用性差等诸多问题。