
Content #
首先来说“写后读一致性”(Read after Write Consistency),它也称为“读写一致性”,或“读自己写一致性”(Read My Writes Consistency)。你可能觉得最后一个名字听上去有些奇怪,但它却最准确地描述了这种一致性模型的使用效果。
我还是用一个例子来说明。
小明很喜欢在朋友圈分享自己的生活。这天是小明和女友小红的相识纪念日,小明特意在朋友圈分享了一张两人的情侣照。小明知道小红会很在意,特意又刷新了一下朋友圈,确认照片分享成功。
你是否意识到这个过程中系统已经实现了“写后读一致性”?我画了张流程图来表示这个过程。
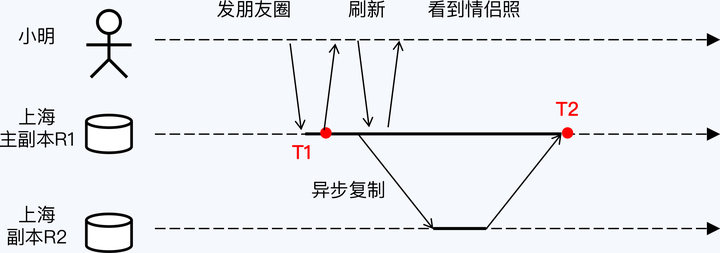
小明发布照片的延时极短,用户体验很好。这是因为数据仅被保存在主副本 R1 上,就立即反馈保存成功。而其他副本在后台异步更新,由于网络的关系每个副本更新速度不同,在 T2 时刻上海的两个副本达成一致。从过程来看,这与前面所说的“最终一致性”完全相符。
要特别注意的是,小明有一个再次刷新朋友圈的动作,这时如果访问副本 R2,由于其尚未完成同步,情侣照将会消失,小明就会觉得自己的照片被弄丢了。此处,我们假定系统可以通过某种策略由写入节点的主副本 R1 负责后续的读取操作,这样就实现了写后读一致性,可以保证小明再次读取到照片。
自己写入成功的任何数据,下一刻一定能读取到,其内容保证与自己最后一次写入完全一致,这就是“读自己写一致性”名字的由来。当然,从旁观者角度看,可以称为“读你写一致性”(Read Your Writes Consistency),有些论文确实采用了这个名称。