
为什么循环嵌套的改变会影响性能 #
说完了分支预测,现在我们先来看一个 Java 程序。
public class BranchPrediction {
public static void main(String args[]) {
long start = System.currentTimeMillis();
for (int i = 0; i < 100; i++) {
for (int j = 0; j <1000; j ++) {
for (int k = 0; k < 10000; k++) {
}
}
}
long end = System.currentTimeMillis();
System.out.println("Time spent is " + (end - start));
start = System.currentTimeMillis();
for (int i = 0; i < 10000; i++) {
for (int j = 0; j <1000; j ++) {
for (int k = 0; k < 100; k++) {
}
}
}
end = System.currentTimeMillis();
System.out.println("Time spent is " + (end - start) + "ms");
}
}
对应的命令行输出。
Time spent in first loop is 5ms
Time spent in second loop is 15ms
这个差异就来自我们上面说的分支预测。循环其实也是利用 cmp 和 jle 这样先比较后跳转的指令来实现的。
这里的代码,每一次循环都有一个 cmp 和 jle 指令。每一个 jle 就意味着,要比较条件码寄存器的状态,决定是顺序执行代码,还是要跳转到另外一个地址。也就是说,在每一次循环发生的时候,都会有一次“分支”。
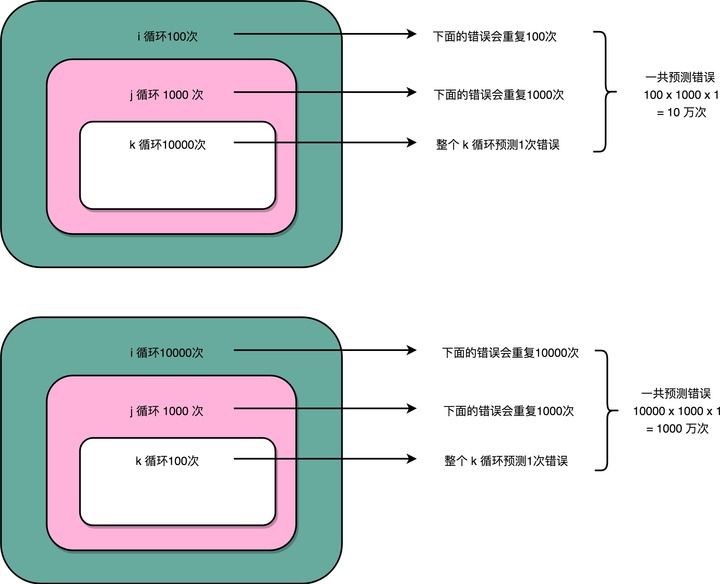
分支预测策略最简单的一个方式,自然是“假定分支不发生”。对应到上面的循环代码,就是循环始终会进行下去。在这样的情况下,上面的第一段循环,也就是内层 k 循环 10000 次的代码。每隔 10000 次,才会发生一次预测上的错误。而这样的错误,在第二层 j 的循环发生的次数,是 1000 次。
最外层的 i 的循环是 100 次。每个外层循环一次里面,都会发生 1000 次最内层 k 的循环的预测错误,所以一共会发生 100 × 1000 = 10 万次预测错误。
上面的第二段循环,也就是内存 k 的循环 100 次的代码,则是每 100 次循环,就会发生一次预测错误。这样的错误,在第二层 j 的循环发生的次数,还是 1000 次。最外层 i 的循环是 10000 次,所以一共会发生 1000 × 10000 = 1000 万次预测错误。
第一段代码发生“分支预测”错误的情况比较少,更多的计算机指令,在流水线里顺序运行下去了,而不需要把运行到一半的指令丢弃掉,再去重新加载新的指令执行。