
Copy GC中DFS与BFS的区别 #
假设,在 From 空间中对象的内存布局如下所示:
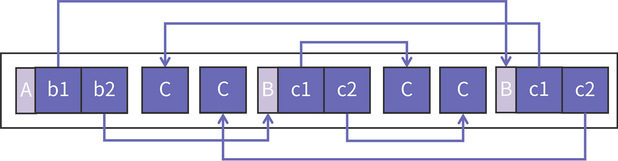 请你注意,图中的空白部分是我为了让图更容易查看而故意加的,真实的情况是每个对象之间的空白是不存在的,它们是紧紧地挨在一起的。
请你注意,图中的空白部分是我为了让图更容易查看而故意加的,真实的情况是每个对象之间的空白是不存在的,它们是紧紧地挨在一起的。
完成了一次 Copy GC 以后堆空间的情况如下所示:
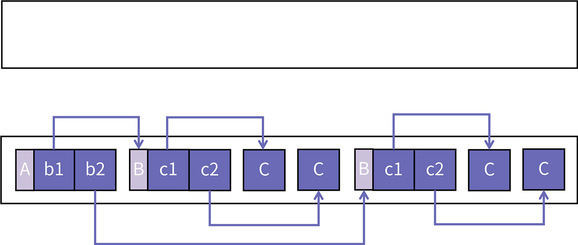 从上面的图片中可以观察到一个特点:To 空间中的对象排列顺序和 From 空间中的对象排列顺序发生了变化。具有引用关系的对象在新空间中距离更近了。
从上面的图片中可以观察到一个特点:To 空间中的对象排列顺序和 From 空间中的对象排列顺序发生了变化。具有引用关系的对象在新空间中距离更近了。
因为 CPU 有缓存机制,所以在读取某个对象的时候,有很大概率会把它后面的对象也一起读进来。通常情况下,我们在写 Java 代码时,经常访问一个变量后,马上就会访问它的属性。如果在读 A 对象的时候,把它后面的 B 和 C 对象都能加载进缓存,那么,a.b1.c1 这种写法就可以立即命中缓存。这是深度优先搜索的 copy 算法的最大的优点。
同时,从代码里也能分析出它的缺点,那就是采用递归的写法,效率比较差。深度优先遍历也有非递归实现,它需要额外的辅助数据结构,也就是说需要手工维护一个栈结构。非递归的写法,可以使用以下伪代码表示:
void copy_gc() {
for (obj in roots) {
stack.push(obj);
}
while (!stack.empty()) {
obj = stack.pop();
*obj = copy(obj);
for (child in obj) {
stack.push(child);
}
}
}
与深度优先搜索相对应的是广度优先搜索。它的优缺点刚好与深度优先搜索相反。如果使用广度优先算法将对象从 From 空间拷贝到 To 空间,那么有引用关系的对象之间的距离就会比较远,这将不利于业务线程运行期的缓存命中。它的优点则在于可以节省 GC 算法执行过程中的空间,提升拷贝过程的效率。
广度优先算法节省空间的原理是:使用 scanned 指针将非递归的广度优先遍历所需的队列,巧妙地隐藏在了 To 空间中。我使用伪代码写出来,你就能理解了:
void copy_gc() {
for (obj in roots) {
*obj = copy(obj);
}
while (to.scanned < to.top) {
for (child in obj(scanned)) {
*child = copy(child)
}
to.scanned += obj(scanned).size();
}
}
其中,obj(scanned)代表把 scanned 所指向的对象强制转换为一个 obj。
综上所述,深度优先搜索的非递归写法需要占用额外的空间,但有利于提高业务线程运行期的缓存命中率。而广度优先搜索则与其相反,它不利于运行期的缓存命中,但算法的执行效率更高。所以 JDK6 以前的 JVM 使用了广度优先的非递归遍历,而在 JDK8 以后,已经把广度优先算法改为深度优先了,尽管这样做需要额外引用一个独立的栈。