
NUMA与UMA #
在多核服务器上,主存也并不是一段平坦的同质的内存。为了加速性能,人们发明了非一致性内存访问(Non-uniform memory access,NUMA),与之对应的是一致性内存访问(Uniform Memory Access, UMA)。
这里的一致性是指,同一个 CPU 对所有内存的访问的速度是一样的,因为物理内存是连续且集中的。而非一致性是指,内存在物理上被分为了多个节点 node, CPU 可以访问所有节点,但是为了提升访问效率,CPU 可以有选择地优先访问离自己近的内存节点。所以在多核处理器上,CPU 也根据内存节点划分成多个组,每个组里的 CPU 访问同一个内存节点的效率是相同的。当然了,任何一个 CPU 都可以访问全部的内存节点,只不过因为“距离”远近的关系,访问效率不一样。
因为 UMA 是基于总线的,CPU 需要先经过前端总线(Front Side Bus,FSB)连接到北桥,然后北桥再连接到内存控制器进行内存访问。如下图所示:
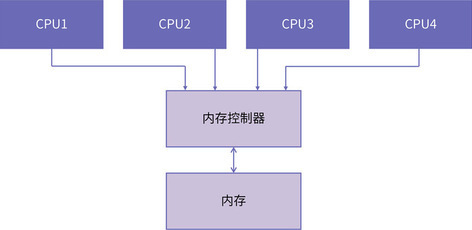 随着处理器核数的增多,UMA 面临的挑战主要包括两个方面:
随着处理器核数的增多,UMA 面临的挑战主要包括两个方面:
- 总线的带宽压力会越来越大,同时每个节点可用带宽会减少;
- 总线的长度也会因此而增加,进而增加访问延迟。
为了解决以上两个问题,NUMA 架构逐渐成为主流。和 UMA 不同,在 NUMA 架构下每个 CPU 现在都有自己的本地内存节点,CPU 与 CPU 之间点对点互联。使用这种方式的典型代表是 intel 的快速通道互联 QPI(Intel QuickPath Interconnect)。如果一个 CPU 要访问远程节点的内存,则先通过 QPI 到达远程节点 CPU 的内存控制器,然后再进行数据传输。
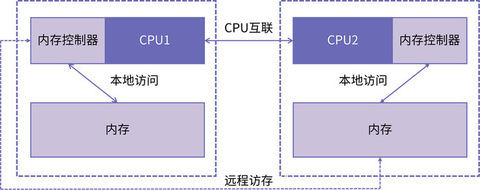 如上图所示,连接到 CPU1 的内存控制器的内存被认为是本地内存。连接到另一个 CPU 插槽 (CPU2) 的内存被视为 CPU1 的外部或远程内存。远程内存访问比本地内存访问有额外的延迟开销,因为它必须遍历互连(点对点链接)并连接到远程内存控制器。由于两者内存位置不同,访问方式也不同,因此这种系统会经历“不均匀”的内存访问时间。
如上图所示,连接到 CPU1 的内存控制器的内存被认为是本地内存。连接到另一个 CPU 插槽 (CPU2) 的内存被视为 CPU1 的外部或远程内存。远程内存访问比本地内存访问有额外的延迟开销,因为它必须遍历互连(点对点链接)并连接到远程内存控制器。由于两者内存位置不同,访问方式也不同,因此这种系统会经历“不均匀”的内存访问时间。
UMA 架构的优点很明显就是结构简单,所有的 CPU 访问内存都是一致的,都必须经过总线。然而它缺点我们再前面也提到了,就是随着处理器核数的增多,总线的带宽压力会越来越大。解决办法就只能扩宽总线,然而成本十分高昂,未来可能仍然面临带宽压力。而 NUMA 在扩展时只需要关注 CPU 之间的连接,不占用总线带宽,自然就成为现代处理器的选择。
SMP架构是指多CPU架构,而不是多核。