
IA-32机器上的Linux进程内存布局 #
在 32 位机器上,每个进程都具有 4GB 的寻址能力。Linux 系统会默认将高地址的 1GB 空间分配给内核,剩余的低 3GB 是用户可以使用的用户空间。下图是 32 位机器上 Linux 进程的一个典型的内存布局。在实践中,我们可以通过cat /proc/pid/maps来查看某个进程的实际虚拟内存布局。
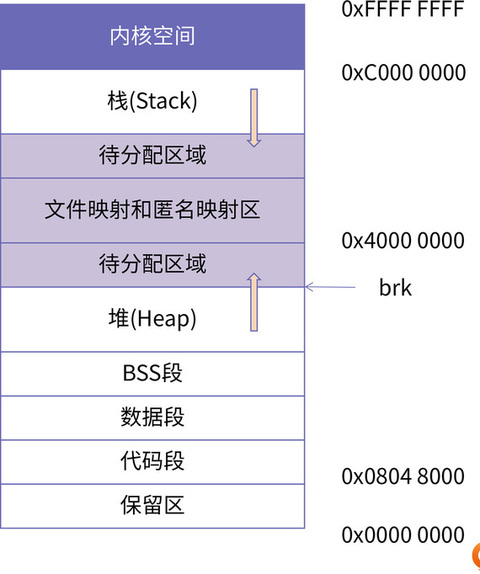
首先,我们发现在 32 位 Linux 系统下,从 0 地址开始的内存区域并不是直接就是代码段区域,而是一段不可访问的保留区。这是因为在大多数的系统里,我们认为比较小数值的地址不是一个合法地址,例如,我们通常在 C 的代码里会将无效的指针赋值为 NULL。因此,这里会出现一段不可访问的内存保留区,防止程序因为出现 bug,导致读或写了一些小内存地址的数据,而使得程序跑飞。
接下来,我们可以看到,代码段从 0x08048000 的位置开始排布(需要注意的是,以上地址需要 gcc 编译的时候不开启 pie 的选项)。就像我们前面提到的,代码段、数据段都是从可执行文件映像中装载到内存中;BSS 段则是根据 BSS 段所需的大小,在加载时生成一段 0 填充的内存空间。
紧接着,排在 BSS 段后边的就是堆空间了。在图中,堆的空间里有一个向上的箭头,这里标明了堆地址空间的增长方向,也就是说,每次在进程向内核申请新的堆地址时候,其地址的值是在增大的。与之对应的是栈空间,有一个向下的箭头,说明栈增长的方向是向低地址方向增长,也就是说,每次进程申请新的栈地址时,其地址值是在减少的。
对此,我们可以想象堆和栈分别由两个指针控制,堆指针指明了当前堆空间的边界,栈指针指明了当前栈空间的边界。当堆申请新的内存空间时,只需要将堆指针增加对应的大小,回收地址时减少对应的大小即可。而栈的申请刚好相反。这其实就是内核对堆跟栈使用的最根本的方式,其中,堆的指针叫做“Program break”,栈的指针叫做“Stack pointer”,也就是 x86 架构下的 sp 寄存器。
继续往下看,就到了内存映射区域,这里最常见的就是程序所依赖的共享库,例如 libc.so。共享库的代码段、数据段、BSS 段都会被装载到这里。