
用cProfile进行性能分析 #
比如我想计算斐波拉契数列,运用递归思想,我们很容易就能写出下面这样的代码:
def fib(n):
if n == 0:
return 0
elif n == 1:
return 1
else:
return fib(n-1) + fib(n-2)
def fib_seq(n):
res = []
if n > 0:
res.extend(fib_seq(n-1))
res.append(fib(n))
return res
fib_seq(30)
接下来,我想要测试一下这段代码总的效率以及各个部分的效率。那么,我就只需在开头导入 cProfile 这个模块,并且在最后运行 cProfile.run() 就可以了:
import cProfile
# def fib(n)
# def fib_seq(n):
cProfile.run('fib_seq(30)')
或者更简单一些,直接在运行脚本的命令中,加入选项“-m cProfile”也很方便:
python3 -m cProfile xxx.py
运行完毕后,我们可以看到下面这个输出界面:
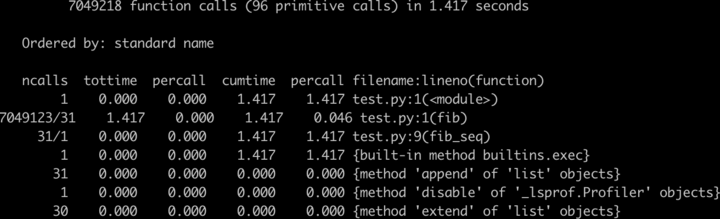 这里有一些参数你可能比较陌生,我来简单介绍一下:
这里有一些参数你可能比较陌生,我来简单介绍一下:
- ncalls,是指相应代码 / 函数被调用的次数;
- tottime,是指对应代码 / 函数总共执行所需要的时间(注意,并不包括它调用的其他代码 / 函数的执行时间);
- tottime percall,就是上述两者相除的结果,也就是tottime / ncalls;
- cumtime,则是指对应代码 / 函数总共执行所需要的时间,这里包括了它调用的其他代码 / 函数的执行时间;
- cumtime percall,则是 cumtime 和 ncalls 相除的平均结果。
了解这些参数后,再来看这张图。我们可以清晰地看到,这段程序执行效率的瓶颈,在于第二行的函数 fib(),它被调用了 700 多万次。
Viewpoint #
From #
31 | pdb & cProfile:调试和性能分析的法宝