
分层编译 #
Java 7 引入了分层编译(对应参数 -XX:+TieredCompilation)的概念,综合了 C1 的启动性能优势和 C2 的峰值性能优势。
分层编译将 Java 虚拟机的执行状态分为了五个层次。为了方便阐述,我用“C1 代码”来指代由 C1 生成的机器码,“C2 代码”来指代由 C2 生成的机器码。五个层级分别是:
- 解释执行;
- 执行不带 profiling 的 C1 代码;
- 执行仅带方法调用次数以及循环回边执行次数 profiling 的 C1 代码;
- 执行带所有 profiling 的 C1 代码;
- 执行 C2 代码。
通常情况下,C2 代码的执行效率要比 C1 代码的高出 30% 以上。然而,对于 C1 代码的三种状态,按执行效率从高至低则是 1 层 > 2 层 > 3 层。
其中 1 层的性能比 2 层的稍微高一些,而 2 层的性能又比 3 层高出 30%。这是因为 profiling 越多,其额外的性能开销越大。
这里解释一下,profiling 是指在程序执行过程中,收集能够反映程序执行状态的数据。这里所收集的数据我们称之为程序的 profile。
在 5 个层次的执行状态中,1 层和 4 层为终止状态。当一个方法被终止状态编译过后,如果编译后的代码并没有失效,那么 Java 虚拟机是不会再次发出该方法的编译请求的。
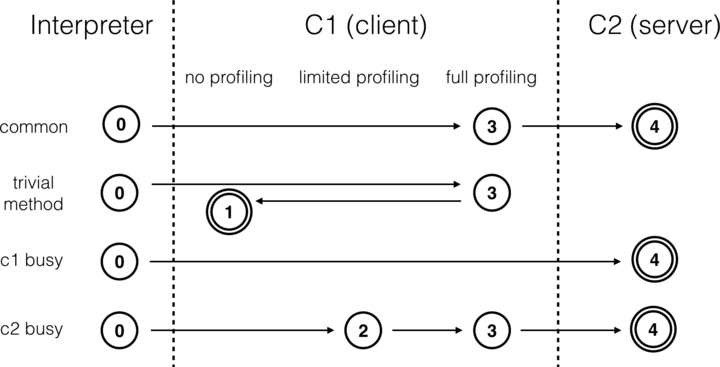
这里我列举了 4 个不同的编译路径(Igor 的演讲列举了更多的编译路径)。通常情况下,热点方法会被 3 层的 C1 编译,然后再被 4 层的 C2 编译。